Day 1 Keynote: The Deep Agents Era – Harrison Chase & Ankush Gola
Speaker(s): Harrison Chase (Co-Founder & CEO, LangChain); Ankush Gola (Co-Founder & CTO, LangChain)
Session: Interrupt 2026 · Day 1 (May 13) · 9:30 AM PT
Source: in-person audio recording, transcribed locally with Whisper large-v3.
Summary
Harrison Chase and Ankush Gola's Day 1 keynote introduces 'deep agents' as LangChain's agent harness that supercharges the core agent loop with batteries-included capabilities. A deep agent combines a model with an execution environment (ranging from a virtual file system to a full code sandbox), built-in context management (skills, memory, summarization, context offloading, prompt caching), human-in-the-loop steering, and delegation to subagents. They launch Deep Agent 0.6 with native open-source model support, a QuickJS-based Code Interpreter as a middle-ground execution environment, and a new streaming protocol, plus the broader agent development lifecycle (build/test/deploy/monitor) backed by LangSmith Sandboxes (now GA), Context Hub, LLM Gateway, Managed Deep Agents (private preview), the new Rust-based SmithDB observability database, and the LangSmith Engine ambient agent. The keynote frames agent traces as the center of the lifecycle and argues memory and context standards should remain open.
Key Points
- Deep agents are an 'agent harness' that adds: execution environment, context management (skills, memory, summarization, context offloading, prompt caching), human-in-the-loop steering, and delegation to subagents
- Execution environment is a spectrum from a virtual file system (a database exposed to the agent as a file system) to a full code sandbox; Deep Agent 0.6 adds Code Interpreter using QuickJS as the lightweight, multi-tenant middle ground
- Deep Agent 0.6 launches native support for open-source models (GLM5, DeepSeek, Nemotron), inference-partner integrations (Fireworks, Base10, NVIDIA), a Deep Agents code example, and a new streaming protocol with four front-end SDKs (CopilotKit, Assistant UI, Vercel)
- LangSmith Deployments has served over 100 million agent runs and is trusted by Workday, Cisco, Etsy, Podium, and ByteDance; LangSmith Sandboxes are now generally available with sub-second spin-up, persistence, snapshots/forks, and an auth proxy that hides API keys from the agent
- New launches: LangSmith Context Hub (versioned agent.md files, skills, LLM wikis as open-standard memory), LangSmith LLM Gateway (beta, spend limits and PII/secret guardrails), and Managed Deep Agents (private preview single API)
- SmithDB is a purpose-built agent-observability database written in Rust on Apache DataFusion and Vortex, backed by object storage for compute/storage separation; it makes observability workloads 6x to 15x faster and is now serving all US Cloud tracing
- Trace scale data: weekly trace volume now over 150M; P50 payload grew 6KB to 37KB and P99 from 364KB to 12MB; one customer sent 50TB in a single day; an internal trace encoded 8.1 million tokens
- LangSmith Engine is a new ambient, proactive, action-taking agent that monitors traces on a schedule, detects and prioritizes issues with trace-backed evidence, and suggests code changes, dataset additions, prompt/context changes, and online evals
Notable Quotes
So what is deep agents? Deep agents is an agent harness, and it basically adds more batteries, included things, than supercharges this loop.
We think memory should not be walked into an LLM, to a framework, or to a platform.
What do you do when you have a lot of really annoying things that are hard and important that you don't want to do? You build an agent to help you with them, of course.
Slides
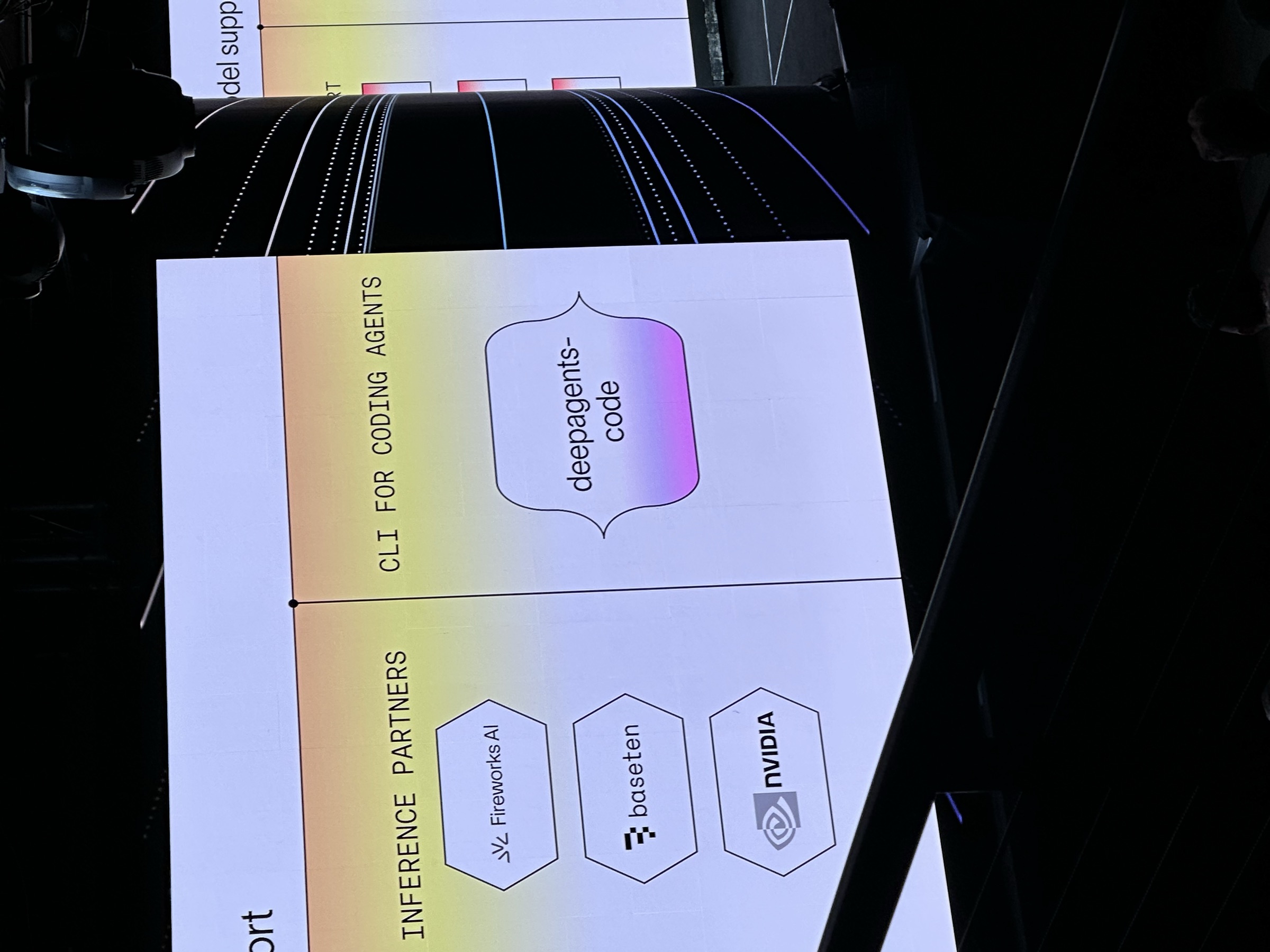 Deep Agent 0.6 ships
Deep Agent 0.6 ships deepagents-code, a CLI for coding agents, with inference-partner integrations (Fireworks, Baseten, NVIDIA).
 What changes from local to production: many isolated users, runtime-injected credentials, per-user persisted memory, RBAC/multi-tenancy, and execution durable across crashes and deploys.
What changes from local to production: many isolated users, runtime-injected credentials, per-user persisted memory, RBAC/multi-tenancy, and execution durable across crashes and deploys.
 The stack to deploy a deep agent: a LangSmith Deployment server plus your choice of model, Context Hub, Sandboxes, MCP servers, and UI (CopilotKit, assistant-ui).
The stack to deploy a deep agent: a LangSmith Deployment server plus your choice of model, Context Hub, Sandboxes, MCP servers, and UI (CopilotKit, assistant-ui).
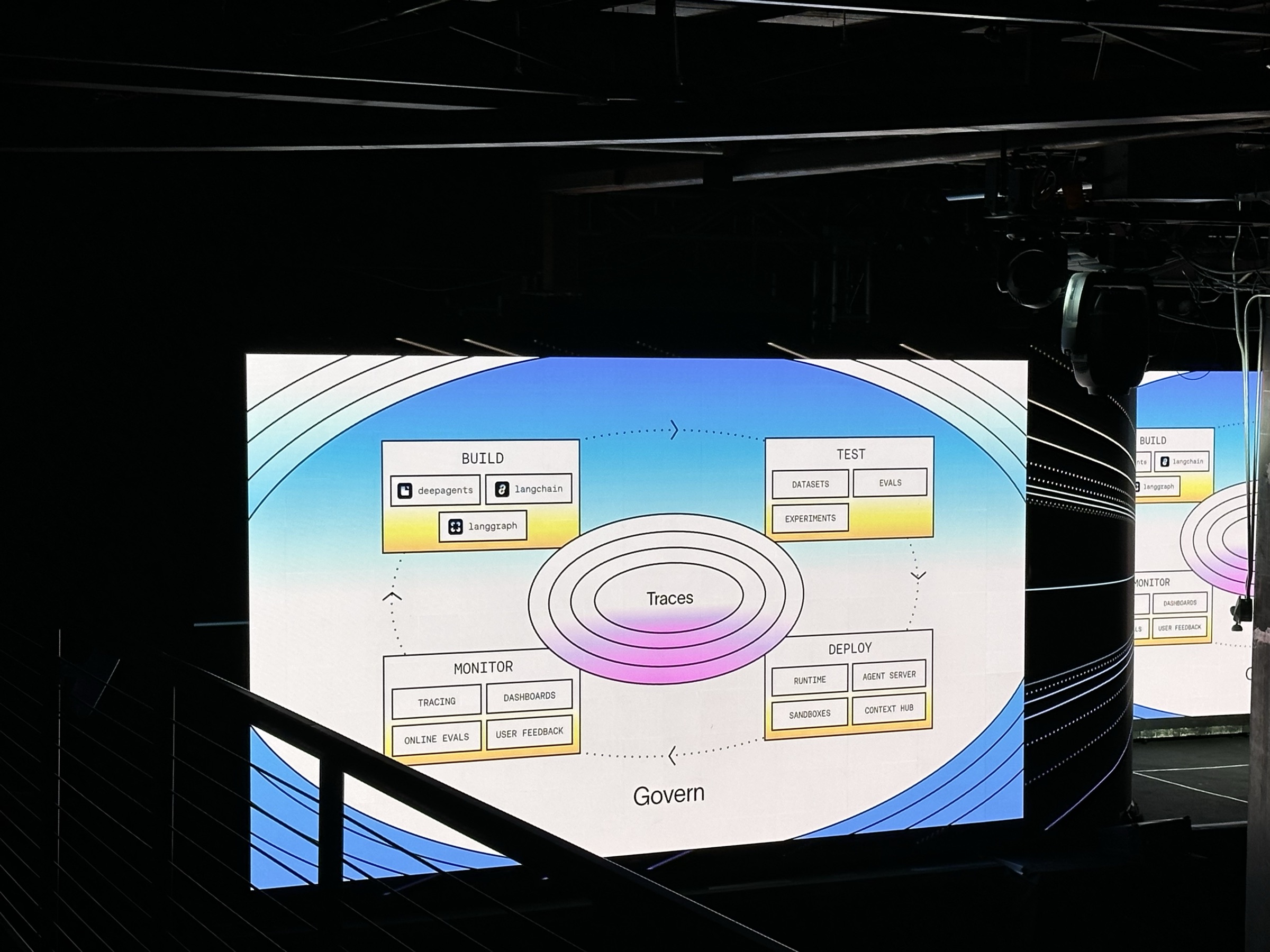 The agent development lifecycle — Build, Test, Deploy, Monitor — with traces at the center and governance around the whole loop.
The agent development lifecycle — Build, Test, Deploy, Monitor — with traces at the center and governance around the whole loop.
 Introducing SmithDB — a Rust, object-storage-backed database purpose-built for agent observability, making trace workloads 6–15× faster.
Introducing SmithDB — a Rust, object-storage-backed database purpose-built for agent observability, making trace workloads 6–15× faster.
 The LangSmith Platform: applications and infra — Observability, Evaluations, Context Hub, Gateway, Managed Deep Agents, Sandboxes — all sitting on SmithDB traces.
The LangSmith Platform: applications and infra — Observability, Evaluations, Context Hub, Gateway, Managed Deep Agents, Sandboxes — all sitting on SmithDB traces.
Full Transcript
Show the full timestamped transcript (auto-generated; lightly cleaned)
[00:00] This is essentially what they're talking about. A user requests content, call the LLM, the LLM
decides to call a tool, you then execute that tool, and you keep on doing that until the LLM decides
that it's finished. That's the core idea of an agent, and that's always been the case. So what is
deep agents? Deep agents is an agent harness, and it basically adds more batteries, included things,
than supercharges this loop. What are some of the things that it adds? It adds an execution
environment. So agent harnesses need a place to run.
[00:31] A really common way to run them is in a sandbox. You give it access to a file system, you give it
access to code, it can read files, write files, execute code. That's its execution environment. So
when people talk about agent harnesses, they often talk about coding engines, and a key part of that
coding engine is its execution environment. Sandboxes are one extreme. You can write and execute
code, and then on the other extreme, we have what we call a virtual file system. This is basically a
database that we expose to the agent as a file system.
[01:05] LLMs are great at reading and writing files, and so you can trick it into having this mock execution
environment. But the point is, you give it an environment in draft mode. Deep agents and other agent
harnesses come with a lot of built-in context management. So skills and memory are examples of this.
Summarization is an example of that. You have a short-term memory. When the conversation gets too
long, you summarize it. Context offloading, how do you deal with really long tool calls? This is
logic that's built into the agent harness.
[01:39] Prompt caching is another example of this, where you want to make sure that you're caching the
initial part of your request so that it can be faster and cheaper in the future. So all this context
management is built into the harness, and it does it automatically for you. Steering is really
important. So these agents, these deep agents, are long horizon agents. That doesn't mean they're
fully autonomous. You still need to keep them in the loop. And so deep agents come with really good
human-in-the-loop controls. And then lastly, delegation. Agent harnesses can be used to kick off
other agents, whether that's planning agents or other subagents with different tasks.
[02:13] And so all of that delegation, communicating with those subagents, having them communicate back to
you, all of that is specified in an agent harness. And so deep agents contains all of these
different things. You spend a ton of time doing this. You both research and apply AI work to make
sure that the way we do summarization is the best, the way that we do subagents is the best. And so
today, one of the things that we're launching is Deep Agent 0.6, a new version of Deep Agent.
There's three big things in it that are informed by three trends that we see in the industry.
[02:51] So one trend we see in the industry is the rise of open models. Deep Seek before launched last week.
And it's just as performant on certain tasks as frontier models. So open source models are getting
better. And the other thing that's happening is cost is rising. The cost of frontier models keeps on
going up and up. And usage keeps on going up and up. And so one of the things that we think will
happen more and more is more usage of open source models. And so with Deep Agent 0.6, we want to
make it the best place to use open source models.
[03:25] So we're launching native support for GLM5, Deep Seek, and Nemotron models. We have the best in-
class integrations with inference partners like Fireworks, BasePen, and NVIDIA. And the easiest way
to try out open source models in a harness is by coding. And so we're launching Deep Agent's code as
an open source example of how to build a coding agent on top of Deep Agent. And we're making it
really, really good for open source models. The second thing that we're seeing is a lot of tension
around the execution environment.
[03:58] So we talked about this. We talked about the virtual file system, which is a really simple way to
let the agent interact with what it thinks is a file system. It's just a pretty simple database on
the foot. And then on the other extreme, you have a full-blown code sandbox where the agent can
write and execute code, spin up a web server, any of that. And so this is a spectrum. But what sits
in the middle? And so in Deep Agent 0.6, we're going to build a code system. And so we're going to
build a code system. And so in Deep Agent 0.6, we're launching Code Interpreter. What Code
Interpreter is, we use QuickJS, which is a JavaScript runtime.
[04:30] And it basically lets the agent write and execute code in this kind of like REPL-like environment.
So it's a subset of the JavaScript language. And you can't do everything that you can do in a
sandbox. So you can't run Docker or things like that. But you can still write and call tools
programmatically. You can manipulate data files. You can read and write from the file system here as
well. And so we think this is a really interesting middle ground where it's super lightweight to
deploy. So this is the benefit of it. You don't have to spin up a separate sandbox for each agent.
You can just deploy this and it's really easy to run in a multi-tenant way.
[05:04] But you still get a lot of benefits that you get from coding. The third trend that we've seen is
that it's still really hard but really important to build the light-full UIs. UIs matter.
Interacting with the agents matter. And one thing that's happened is these agents have gotten more
and more complicated. And the events that they're emitting are correspondingly more and more
complicated. They emit text. They emit tool calls, images, reasoning, sub-agent stuff, how to do
that. And so we want to make it as easy as possible for people to run agent harnesses and hook them
up to the light-full UIs that they build for their customers.
[05:38] And so the third launch in DeepAgent 0.6 is better support for streaming. So we have a brand new
streaming protocol. We have four different front-end SDKs for different front-end languages. And
we're partnering with UI frameworks like CopilotKit, Assistant UI, and Vercel to make sure it's
really tightly integrated. UIs are a big part of building agents and we want to make it the easiest
way to do so. So if you haven't already tried out DeepAgent, please go try it out today.
[06:08] This is where we think the future is heading. These engagement harnesses are getting more and more
robust, more and more production ready. And DeepAgent is our version of that. I want to talk about
the test phase next. So you build your agents. How do you know if it's actually working? This is
where links with evaluations comes in, something we've been building over the past few years.
Testing for agents looks different than testing for software. You want to build up data sets, so
reference inputs and reference outputs, or maybe criteria to score how it's doing.
[06:44] You want to define metrics. How do you know if the agent is passing? This could be correctness. This
could be hallucinations. But you want to define some metrics that work for your use case. And then
you run your agent over these data sets and you score them on these metrics and you create these
experiments. You can use these experiments to hill climb on certain things. Or you can use them to
make sure that you're not regressing as you're making changes. Evaluations are a key part of links
with. And we're launching some stuff around this today, but I'm going to talk about that later.
[07:14] So I'm going to go on to deploy next. So you've built your agent. It's running locally. Now you want
to go to production. There's a bunch of challenges that are going to emerge as you do that. First,
you have to go from a single user, just you. Now you're serving many in production. Environment
variables and memory, these now have to be specific to the users that you're interacting with. Off,
you need to control. You can access it. You can't just open it up to everyone. And then when it runs
locally and it dies, you're just testing it and you can resume from there. But you need to run it
durably when you're running it at that scale.
[07:46] And so a year ago, we launched links with deployments. To help with this. So there's a bunch of
features built into this. We launched about 30 different API endpoints that handle streaming, human
in the loop, off, other things like that. It's a single standard deployment pattern. Today it's
served over 100 million agent runs and it's trusted by companies like Workday, Cisco, Etsy, Podium,
and ByteDance. But we also realized that links with deployments isn't the only thing you'll need to
bring an agent into production.
[08:17] We've talked about this. We've talked about how agents need an execution environment. And one of the
best execution environments is a sandbox. So whether the agent is a coding agent or not, reading and
writing code can be really impactful for the agent. It can manipulate data that way. It can use CLIs
that way. And so we generally think that a lot of agents will need the ability to write and execute
code in sandboxes. And so today we're excited to announce that links with sandboxes is generally
available. We think this is a big part of agents in the future and so we made it really easy.
[08:55] You spin up sandboxes in less than a second. There's persistence for these sandboxes so that will
survive across interactions. It supports snapshots and forks. One of the coolest things we've done
is this off proxy. So if you want to give the LLM, the agent, the ability to use something that
requires an API key, you don't actually want it to see that API. Because then it could get prompt
injected and leaked it. So we have an off proxy that sits outside the sandbox and basically
intercepts traffic and inserts that in. And this is all part of the links with SDK. It's completely
framework-agnostic.
[09:26] So you can use it with deep agents. You can use it without deep agents. You can use it for testing
agents. You can use it for RRL. You can use it for running agents for production. We're really
excited to see how people use it. We've already had a number of customers using it. Monday, for
example, uses it for their AI assistant sidekick. And we're excited by the feedback that we've
gotten so far. Another big part of bringing agents to production is context. So LLMs by themselves,
they don't know anything. Or they don't know everything.
[09:57] Humans don't know everything. When we need to look up things, we go to a library. We look at books
to learn things. We read them. And that's exactly what agents do as well. They do that with context.
And that context has evolved over the years as LLMs have gotten better. So we had a prompt hub in
Lane Smith for the longest time where you could store and version prompts. And prompts are the
thing. And prompts are the things that kind of like guided agents. But over the past few months and
year or so, we've seen that the context provided to agents has graduated from prompts into things
like agent.mp files.
[10:28] So really detailed instructions and skills that these agents have used. A lot of these are shaped by
coding agent standards. Both of these are open standards, by the way. So they're part of open
foundation. And so as the context that LLMs have needed has evolved from prompts into these agent.mp
skills. So has our tooling for that. So today we're excited to launch Lane Smith context hub. And so
what's in this context hub?
[10:59] So you can take your agent.mp files. You can take your skills. You can take your LLM wikis. So this
is the thing that our coffee did where we basically ran an LLM and had it generate wikis and share
it with our dense knowledge. And then mark down files. We think that's going to become a more and
more common pattern. So you can take all of this. You can store it in context hub. You get
versioning. You get tag. You get comments. And then you can use these. You can pull them down
locally. You can run them in your coding CLI. You can run them in deep agents as a virtual file
system so we have an integration there.
[11:29] Or you can use them in whatever agent harness you have. We think context hub is a first start at
memory. We think memory is really, really important to agents in the future. We think agents.mp and
skills, you can absolutely view those. As an early form of memory. And those are open standards. So
that's a great thing because we think memory should be open. We think memory should not be walked
into an LLM, to a framework, or to a platform. And so even though we're building context hub, we
want this idea of context to be really open.
[12:01] And so we're working with a number of companies including Redis, Elastic, Mongo, and Time Tone to
turn this first stab at memory into something that's an open standard for us. So we think everything
should be open. And lastly, we've got Monitor. So you've launched it, but how do you know what the
agent's actually doing? This is where a lot of the core links to functionality around tracing.
[12:31] So you can make sure that you can see the stack of every agent and what the inputs are and what the
outputs are. Dashboards so you can track cost and latency over time. Online evals so you can run LLM
as a judge. Or free. Or code over these traces. Get some feedback and attach that. Or just capture
user feedback. All of this is part of links with observability. We've been building a lot here over
the past few years and over the past few months. We've got a few very big launches here, but we're
going to save that for a little bit later. So this is the agent development lifecycle.
[13:03] And this is what it makes. This is what it looks like to bring agents and maintain agents in
production. And when you do it once for an agent, that's fine. And you do it for 10 or when you do
it for 100 agents. That's when you really need to start to think about the governance of all of
this. How do you do this at scale? How do you do this in a cost efficient and secure way? And so
specifically, two of the concerns that we've seen emerge around governance over the past few months
have been cost and data exposure. LLMs are getting expensive. How do you know how much agents are
spending, how much specific users are spending on agents, and how do you avoid surprise bills?
[13:38] On the data exposure side, LLMs are great at working with data. But they shouldn't be able to access
every source of data. And so how do you control what they can and can't see? Today, we're launching
Lanesmith LLM Gateway in beta to help with that. You guys can't just pick and choose which synonyms
you can clap for. They're all great. So what is Lanesmith LLM Gateway?
[14:08] So you've got your agents. They're running. Lanesmith LLM Gateway is a platform. LLM Gateway
basically sits between them and their LLM calls. You can set spend limits. You can have visibility,
total visibility over spend. And then you can also set guardrails to help with PII and secret
detection. It integrates with a bunch of coding agents out there. So you can use it. We know that
coding agents is the most popular thing that people are using. And that's where a lot of these costs
are happening. So we've made sure to integrate it with a lot of coding agents out there. It
integrates with all the LLM providers that lane change can help you access.
[14:40] And then you can see how everything is traced automatically to LLM. So this is the full agent
development lifecycle. Everything that we're building kind of fits into this. And we recognize that
there's a lot in here. Taking an agent and going through production and going through this lifecycle
involves a bunch of different pieces. And so we want to make it as easy as possible for people to
take all these pieces. Take deep agents, which is our agent products under the hood. And really,
really easily go to production. And so to make that into a single API, today we're announcing in
private preview Managed Deep Agents.
[15:22] So Managed Deep Agents is a single API for interacting with all these different components. So it
runs the deep agent harness under the hood. It's deployed with linksmith deployments. And so that's
where the agent will run. The models that you can access include any models out there. So we
obviously integrate with OpenAI. We've got the OpenAI and the Profic. But also with the open source
small providers like Fireworks and Base 10. All of the agent instructions and memory are stored in
context top. So that as you or your users or the agent itself updates them, you can see them there
and version them there and back them there.
[15:56] These agents, when they're deployed, you basically want to deploy the agent over here. And then give
it access to a sandbox to run and write tools over here. And you want those to be separate. And so
that's the architecture that we go. And we use linksmith sandboxes to help power those sandboxes.
MCPs are how you connect them to tools. So you can provide MCPs directly. Or you can use Arcade or
another partner that provides access to a lot of MCP servers to do that. And all of this streams out
in the new streaming protocol that we announced. So you can integrate it super seamlessly with
CopilotKit, Assistant UI, and other frameworks.
[16:30] So combining everything. Langchain open source and linksmith power this whole agent development
lifecycle. And we think that traces sit at the center of this lifecycle. And so we spend a lot of
time as a company thinking about traces. And thinking about how to build the best experience around
them. Everyone does. But there's no one at the company who thinks more about traces than my co-
founder, Onkush. He's been thinking for the past almost a year about how we can make the experience
around traces the best possible experience.
[17:05] Because this is what powers that whole thing. And so we're launching a lot of really cool things
around this. But in order to talk about traces and his love of traces, I'd like to welcome onto the
stage my co-founder, Onkush Gopal. Hey everyone. I'm Onkush.
[17:37] Co-founder and CTO here at LinkedIn. As Harrison mentioned, I do spend a lot of time thinking about
agent traces. And that's because we really think that agent traces are at the center of the agent
development lifecycle. Each agent trace captures the unique behavioral record of what your agent
actually did at a specific point in time. That being said. Agent traces, or more generally agent
observability, poses the unique data infrastructure problem.
[18:14] For one, agent traces are very deeply nested and can contain thousands, if not tens of thousands, of
intermediate steps. The payloads associated with agent traces are large and unbounded. These two
characteristics of agent traces are a direct result of the data that's being collected. And so we're
going to talk about that. The first is the result of agents running for longer time horizons and LLM
context window sizes getting larger and larger. We're seeing an increased number of agent traces
being logged with modalities such as images and voice.
[18:53] Voice is getting especially popular with applications like Customer Support. Finally, the access
pattern, or the query pattern needed to effectively monitor the data. To effectively mine your agent
traces for useful insights are unique and complex. Agent traces are not only encoding more
information and getting more complicated, they're also growing in volume as agents become more and
more ubiquitous.
[19:24] Here's the figure that highlights the real lengths that customers weekly trace volume over time. As
you can see, in the early stages, the data was not only being used to track the data, but also to
track the data itself. And so we're going to talk about the process of tracking data. In the early
stages of testing and development, the weekly trace volumes are relatively small. But as the agent
enters production and as new agents enter the picture, the weekly trace volume that we now see is
over 150 million. So as mentioned earlier, the payloads associated with agent traces are large and
they're getting bigger over time.
[20:03] Over the past couple of years, we've seen the P50 payload size associated with agent traces that the
bank spent grow from 6 kilobytes to 37 kilobytes. And P99 has grown from still a pretty sizable 364
kilobytes to 12 megabytes a day. And another data point, earlier this year, we had a single customer
send us 50 terabytes of trace data on a single day. That's quite a lot of data.
[20:38] This video highlights what a modern agent trace enhancement looks like in practice. As you can see,
lots of intermediate steps, very deeply nested. This trace is actually pulled from one of our
internal market agents that's built with deep agents. And another thing to point out is that this
trace actually encodes 8.1 million tokens. Traditional data infrastructure was not built for the
challenges associated with agent observability.
[21:12] If you're using suboptimal infrastructure to handle agent observability workloads, you will
experience slow queries and ingestion problems. You'll also experience rising infrastructure costs
and complexity as you try to scale up. When you're iterating on your agent, you cannot afford to
have two. You can't afford to have three. You can't afford to have four. You will have to close that
material from your agent сь
[21:45] You won't be allowed to have six. You cannot afford to have a hundred. You can't afford a hundred.
To put his in one unit. You want to read a thousand. You'll run into minimum needs within six
months. It's a fairly high price to have all of that lashes and straps for� wedding. You can't
afford that. Kitty needs to have everything that Ginette. They've got to have all of that. Each in
one package of hardware. It seems a populace all- calorie air constituting, but actually, most
people, regardless of her weight and proportion to weight in general, make up about twice as many
todas that are involved. So here we're talking about 2.5 million tokens. video of the funnel of the
form. Introducing SmithDB, the database purpose field for agent observability. This is a trace, a
record of what your agent does, how it thinks, decides, and performs. Now, imagine thousands of
them, millions growing each day,
[22:18] because agents are everywhere. The problem is that traces aren't like traditional logs and metrics.
They're larger, deeply nested, multimodal, and you don't query them the same way. If you're
searching across text and meaning in traditional databases, they weren't built for this. So as the
traces grow, searches slow until now. SmithDB, the database purpose field for agent observability.
Search across full-text content, query entire agent
[22:48] conversations, access complex data instantly and at scale. Check out. Building reliable agents
requires rapid iteration. With SmithDB, you can move from data to data to insight to improvement
faster. That video got me pretty hyped up, not to lie. Whoever is creating our video is doing an
amazing job.
[23:19] So now let's take a closer look at what SmithDB actually is and how it's architected. The first
thing to point out is that SmithDB is backed by OpEx storage. This gives us a few nice properties.
First, object storage is incredibly cheap, and it scales pretty much instantly. The second is it
gives us what's called compute storage separation. This allows us to elastically scale the services
that that's in the DB without any complex shuffling or charting
[23:50] of data as you scale up the services. Third, this gives us an architecture that is relatively easy
to set up and help those environments where data reference requirements are strict. Now, at a high
level, the length of the services net this in SmithDB after getting assignments from our cluster
manager. Our cluster manager helps ensure that load is evenly distributed across our servers, and it
also maintains some semblance
[24:23] of what's called figure routing. Figure routing is important because it helps utilize the patch, and
it also helps batch our data effectively for ingestion. So during ingestion, raw data, trace data
comes through our ingestion service. It gets batched, and it gets hurriedly stored into OpEx
storage. These files are registered in a Postgres-backed metastore. At query time, we figure out
which files are necessary to be scanned for the queries. We download them from OpEx storage, and we
scan them.
[24:56] We also heavily utilize SSD caching and memory to minimize round trips to OpEx storage. Finally, we
have a caching service that helps shape our files for more optimal experience. SmithDB is
specifically designed for agent observability access patterns. We'll walk through some of these
access patterns in the next slide. SmithDB makes plugging into individual phrases and
[25:26] individual intermediate steps really snappy and fast. Agent observability isn't just about asking
what happened across millions of traces. It's also about asking, you know, what happened in this one
particular agent execution. That's why random access is really important and something that we've
optimized in SmithDB. Agent traces contain megabytes of text data.
[26:00] And oftentimes, you need to search across your agent traces using keywords or phrases. As you can
see, SmithDB makes full text search really snappy and interactive. To accomplish this, we've
actually built a custom inverted index layout specifically designed for OpEx storage. Agent
interactions are often multi-terrain in nature.
[26:30] This is why threads are a first class primitive within Lake Smith. Now that threads are back-traced
in SmithDB, you can see how snappy and interactive it is to drill down into multi-terrain agent
interactions with Lake Smith. In agent observability workloads, you often need to pick a specific
time horizon and apply filter settings to the client. You can do this by adding filters to the
client, like on metadata, tags, names, latency, and other attributes.
[27:01] Scanning and filtering speed is something that we've highly optimized within SmithDB. And as you can
see, the results are nearly instant. We're incredibly pleased by the performance that SmithDB brings
with the length span across these key agent observability workloads. Compared to before SmithDB,
we're able to do more than just look at the length span of the client's workflow. These length span
workloads are now anywhere from 6x to 15x
[27:31] faster than before. This is absolutely magical. But look, don't just take our word for it. We're
super lucky to be working with customers like Clay and Vanta, who were early adopters of SmithDB
until Lake Smith. As you can see, Jeff from Play and Andy from Manta both state how SmithDB has
completely transformed their experience, interacting with their traces within length.
[28:07] So SmithDB is purpose-built for new generative ability, and we built it using a modern tech stack.
The entire system is written in Rust, and we used two awesome open-source projects. One is called
Apache Data Fusion, which is an extensible, Rust-based brain. The second is Vortex, which is an
extensible file format that allows us to pick custom encodings and custom jumping strategies for the
different columns that we store. On top of this foundation, we have heavily, we've added some heavy
customizations around indexing, specifically for full-text search.
[28:47] We've added custom query plans. We've added custom branding and execution plans. And we also have
invested in custom storage layouts for all the data that we're storing within SmithDB. Here are some
of the technical challenges that we've had to solve when building SmithDB. There's just a few of
them. There are quite a lot, but I've got to choose. So in HM-Zerbability workloads, your spans are
distributed.
[29:17] They come in different parts. This is because agents run for a long time, right? Right. And so you
can have a start event that starts, or that gets sent sometimes hours before you're into them. And
so finding and merging these distributed events together at query time and at compaction time is a
technical challenge that we had to solve. Doing it efficiently is something that we've confessed to
a lot of times. A lot of the queries that are linked in that are top-paced algorithms.
[29:49] So they contain an order by and limit. And a more naive query plan would essentially be like find
all the files that are in range and scan them out, scan them, do some type of merge and top-pay
operation. This is actually like a little bit expensive on object storage. Actually quite expensive
on object storage. So what we've done is we've taken a time window-based approach and encoded that
in a custom execution plan that feeds top-paced algorithms. And we've made it within an E.
[30:23] Finally, in observability workloads, you often need to serve the most recently ingested data as fast
as possible. Right? And in order to do that, what we do is we buffer data in the ingestion service
even after it's been thoroughly flushed through object storage. And we buffer it in memory and on
SSD. And we make that data available to the query side. And we do that in the query service to avoid
downloading a ton of small files for leading-edge software.
[30:56] Langsmith performance is not only important for human UX but also agent-wise. Increasingly, agents
are not just a thing that are being observed by Langsmith. They are also the users of Langsmith. And
it's a huge hit to have your agents slowed down by inefficiency. I really like this quote from Jeff
Dean who states that, you know, as we get agent-based systems that are operating multiple times
faster than a human, your tools can become like an Amdell 12 problem.
[31:37] We're super excited to announce that SmithDB is now serving four observability workloads across all
of US Cloud. So if you're using Langsmith on smith.langstd.com, all of your interactions and your
tracing projects page are now powered by SmithDB. Soon... We're working quickly to get the rest of
the Langsmith UI back to SmithDB.
[32:09] And we're going to bring it soon to self-hosted and across all of global cloud traffic. So SmithDB
sets up a lot of different tools. So SmithDB sets a really, really strong technical foundation for
everything that we want to build into Langsmith. And to share some more exciting updates about
Langsmith, I'd like to welcome Harrison back on stage. Thank you so much. SmithDB is absolutely
incredible.
[32:43] As you can see, I have a lot of experience with it. As you can see, I have the fun and easy job of
just talking about what we built. But Anquish and the whole team there goes out and builds really
complex engineering projects and databases that help power everything in the life cycle. And that's
really how we think about what we do. We want to accelerate everything in this life cycle. We think
traces and SmithDB are a key part of that. And so we just saw the foundation. A big part of what
we're thinking about now is how can we accelerate this life cycle even more.
[33:14] Because even with traces, even with the durability, the visibility that it provides is table stakes.
Being able to see what your agency did at each step is absolutely needed, but that's table stakes.
It's still hard to spend this iteration quite well. Finding issues among the tens of thousands,
hundreds of thousands, millions of traces that you have is still hard. Once you find those traces,
understanding issues in them is still hard. It's still hard. And it's still hard for you to
understand and be able to understand the problems that you face.
[33:44] still hard, they can be really really long, you have to comb through them and see exactly where the
LL is messing up, where it's all in the wrong pool. Once you understand that issue, fixing them is
hard. You want to change the prompt, you want to change the code, you want to change some tools,
there's a bunch of different things that you have to investigate and try to tie back to the core
issue. And then once you fix it, avoiding repeating these issues is hard. Sometimes it can feel like
whack-a-mole, you fix one thing and then you change the prompt and it reappears. So how do you avoid
this? And so we spend a lot of
[34:18] time thinking about how we can spin off this flywheel faster and faster because it is still hard.
All these things I mentioned are still annoying. And so what do you do when you have a lot of really
annoying things that are hard and important that you don't want to do? You build an agent to help
you with them, of course. And so that's why today we're really excited to launch this project. We're
going to launch an agent in Langsmith, an ambient, proactive, action-taking agent that we're calling
Langsmith Engine.
[34:56] Specifically what it does is it will sit on top of your traces. It'll go through them on a schedule
in the background. It will detect issues and assign a priority to them. It will back its evidence
with traces. And then it will suggest concrete, concrete, concrete resolution actions. We've been
working with a number of startups over the past few weeks. For Roll is out with us. And as you can
see, it is already proactively suggesting evals to add and code changes to make. And then
dramatically reduced time to detection and
[35:28] time to triage. So specifically what engine can do, it acts at all stages of its lifecycle. So it
sits on top of traces. It can suggest code changes if you hook it up to your GitHub or Codemate. It
can suggest data points to add to data sets so that you can use these to avoid regressions in the
future. If you connect it to prompt or context hub, it can suggest changes there. And then it can
also suggest online evals to add so that you can track these issues over time. Let's see a little
video of it in action.
[36:38] Thank you.