Multi-Agent Frontiers - Building Ask D.A.V.I.D.

Zheng Xue


David Odomirok
Summary
Zheng Xue and David Odomirok from JPMorgan Chase discuss "Ask D.A.V.I.D." (Data Analytics, Visualization, Insights, and Decision management system), an AI-powered multi-agent system designed to automate and enhance investment research. The system addresses the manual and time-consuming process of answering investment questions by leveraging decades of structured data, vast unstructured data (emails, meeting notes, recordings), and proprietary models. The Ask D.A.V.I.D. architecture features a supervisor agent that orchestrates tasks by delegating to specialized sub-agents: a structured data agent (translating natural language to queries/API calls), an unstructured data (RAG) agent, and an analytics agent (using proprietary models and APIs, with human supervision for complex queries). The system personalizes answers based on user roles and includes a reflection node using an LLM judge to ensure accuracy, retrying if necessary. Key learnings from their development journey include:
- Start Simple and Refactor Often: Begin with a basic agent (e.g., ReAct) and iteratively build complexity, integrating specialized agents into a multi-agent flow with supervisors.
- Evaluation-Driven Development: Crucial in finance, continuous evaluation (independently for sub-agents and the main flow) with appropriate metrics (accuracy, conciseness, trajectory) helps build confidence and track improvement. They emphasize starting evaluation early, even without ground truth, and using LLM-as-a-judge combined with human review.
- Keep Humans in the Loop: For high-stakes financial applications, achieving 100% accuracy with AI alone is challenging. Human oversight is vital, especially for the "last mile" of accuracy, ensuring reliability when billions of dollars are at stake.
This approach allows JPMorgan to scale their investment research capabilities, providing precise, curated answers and insights in real-time.
Auto-Highlights
Auto-Highlights: Highlight: agent AI, Count: 1, Rank: 0.07 Highlight: Same agents, Count: 1, Rank: 0.07 Highlight: multi agents, Count: 2, Rank: 0.06 Highlight: multiple agents, Count: 1, Rank: 0.06 Highlight: specialized agents, Count: 1, Rank: 0.06 Highlight: inter agent context, Count: 1, Rank: 0.06 Highlight: dog search agent, Count: 2, Rank: 0.06 Highlight: machine learning predictive AI models, Count: 1, Rank: 0.05 Highlight: use cases, Count: 6, Rank: 0.05 Highlight: customer experience, Count: 5, Rank: 0.05 Highlight: machine learning models, Count: 1, Rank: 0.05 Highlight: custom AI models, Count: 2, Rank: 0.04 Highlight: more questions, Count: 1, Rank: 0.04 Highlight: investment questions, Count: 1, Rank: 0.04 Highlight: salesforce customer experience, Count: 1, Rank: 0.04
Photos

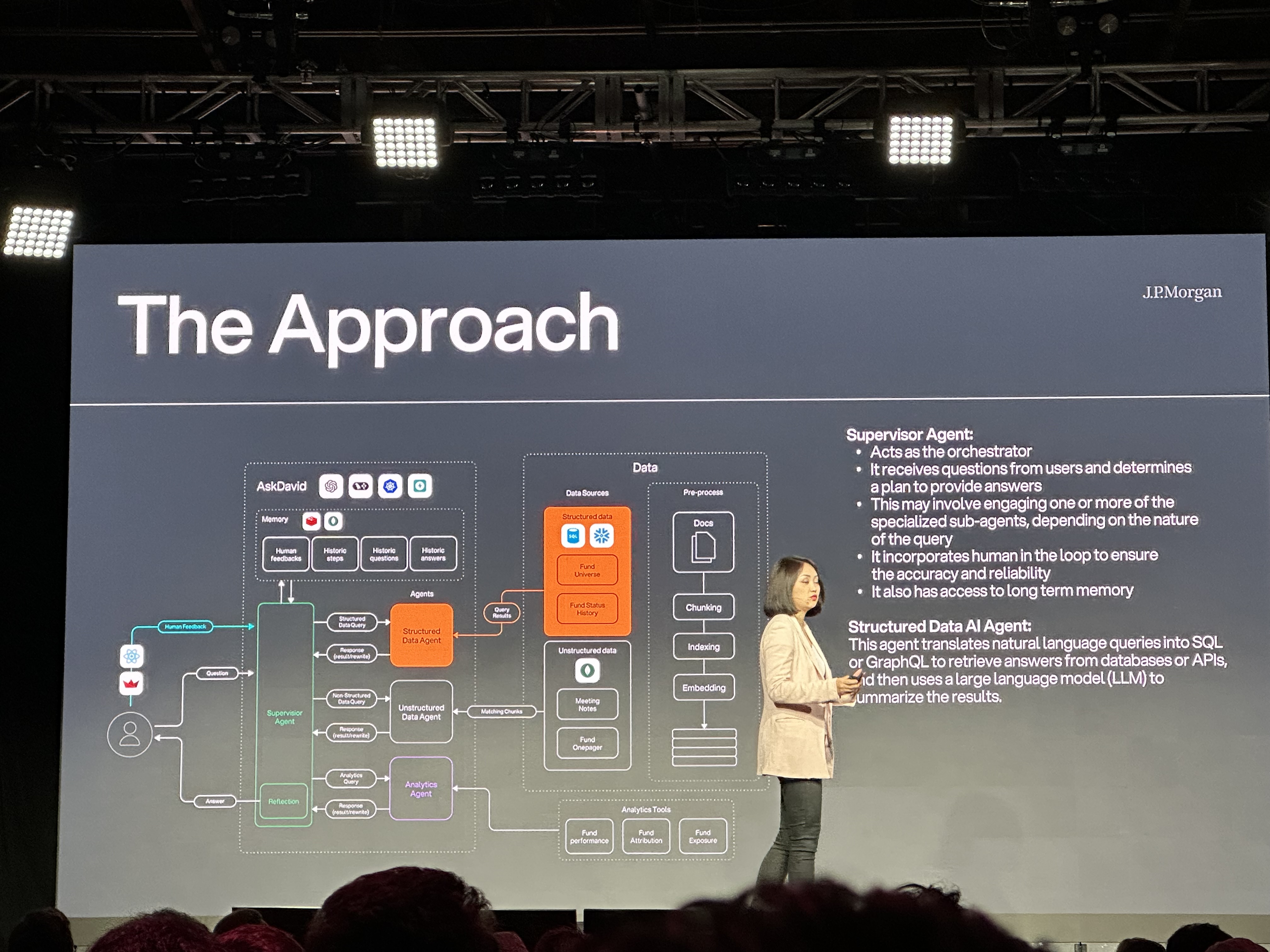
Transcript
...and with that I'd like to introduce Zheng Xue and David Odomirok from JPMorgan Chase.
...and actually there are three fold organizations that go to that. So you have a customer success organization that actually is in charge for when someone acquires something. For Cisco Fire product there is an adoption team that makes sure that you adopt whatever you buy right and there is an organization that is reused to make sure that when the end of the term comes you are happy enough to actually renew subscription. And usually more often than not during that period we expand our relationship with the customer. There is obviously technical support which a lot of you mention this and other organizations like implementation cell cl I'm talking about 20,000 people organization north of us. So there's a lot of things that could be improved and from that lens what we are doing is adopting AI to help us not only on optimizing the process but optimizing for people and maximize the returns of business. And that's a very important thing because if you look at the left hand of this slide I'm talking about how we make customer experience unimagina and by that I'm going to hyper personalization proactiveness but we are not talking about Agent Ki overall it doesn't come out of the blue and like hey Genki is a new thing. We start with machine learning predictive AI models over a decade ago so treat very well your data science team because they're going to be critical now then we come for the LLMs gen AI which are very good for everything that has to do with interactions on language. There is an L on the read obviously for a reason. LLMs really bad for predictions. So when you bring this together we can have multiple agents that goes for workflows. So with that said our vision and the future of salesforce customer experience and you have been living on this for over two years now and a lot of companies are coming to help understand how we're doing this. And that's part of the reason why in this conference on the dariusnoff partnership we have with Harrison and his team we are going forth using agentic AI to elevate CX to become an agentic CX by providing personalized predictive and proactive experience to all of our users together, not separately output personalization how we can predict fails before they happen how it can be interactive of field notice or even best practice that goes there. We are leveraging multi agents by multi agents you can assume next slide what I mean by that there's human and machine type of agents gen AI contributionary we are providing services that goes for users that call them like you can call on a video Call on a chat interface or a phone call or they have a tool tool for API calls and MCP calls and the agency CX provide a lot of embedded value like advanced technical support, predictive intelligent operations. And all of this is meant to help customers to have recommendations that are proactive. So we want to avoid them to face an issue if we can approach. We want to give them predictive insights and make this hyper personalized foresight in a sense that every customer should have an agent on themselves which has context for that. So context is a very important thing for us and we are going beyond what we call about MCP complex. It's a big thing that is out there. With that said, let me go now that you're all Ph.D. what we do at Cisco, let me talk a little bit about use cases and why we drive on a use case approach as a opposed to a tools approach. So just sharing an experience for here when you start about a year and a half ago obviously GPT was a big name in town and everybody was trying to try GPT 3.0 was back then but the steel was not right. Completely normal. But before we had everybody trying to do a chatbot for whatever reason it was so the first things before we even built a use case we define the criteria that would make the use case belong in the first place because we have an advisory part of our services. We enter a customer that the customer had 412 use cases for AI and when you talk with them ends up being five that actually collaborates with the this is less than 10%. So we define a criteria to say any use case that we do a customer experience. Remember that it comes into organization with a lot of creative people and a lot of ideas. Right. It must fit one of those three buckets. We must have use case to help customers then immediate value and maximize what they investment us. And that's where renews and adoption as an agent goes in. Same applies on how we make the operations people more secure and reliable. That's where everything we support will go in and then the whole correlation and agency workflows provide visibility and insights across the whole life cycle. So there is a method to the maintenance here. If you think and if you leave it alone, people are going to do their own thing and it's going to come to you and say hey, here's how cool it is. So how this manifests to the business. So define the use case criteria first then put the use case on top of this and that's how we restructure the mortal Blankchain because now we stitch the pieces because the agents develop a good organization make sense to the customer. So with that said we obviously have a high level stack. I can go into details. We have a team on the booth that goes deeper including on what we demo yesterday. So we start with the need for our use case to have flexible deployment models. What I mean by that we have customers like federal customers, health care and some others that requires on premises deployments. By on premises I'm not talking a VPC on Ars and I'm talking physical data center. We have clouds and we have hybrid on it. So we need to choose some criteria like security compliance. There are customers in Europe that have heavy regulations. There are some others that are more B2C the bulk of our business is B2B business to business, not only business to consumer. So when you do for that we start to power the best in class AI technology. So we chose Mistral Large and we worked very closely even to the developer of their models to run on premises. And we have both Sonnets, the latest from Sonnet 3.7 and GPT ChatGPT from 4.1 all the way to 03 for some of the use cases that is empowered altogether for LangChain in the demo you're going to see that we have the same agent framework running on premises on a Data center and 100% of the cloud without any change. So what he's saying on the belief we'vebeen doing this in production for a long time that scale so what Harrison said is not high level, it actually works. It's an interesting thing and we use the agentics on multiple regions on the top and we did end up doing custom AI models By custom AI models I'm talking about both creating machine learning models there for predictions that you train for the signals and fine tuning LLMs especially the on prems to accomplish high accurate sum of our with that said here I want to do one slide before I deep dive on some of the tech aspects. So remember that I mentioned to you the process land adopted spend review and the people so now I'm going to learn the technology on top of that. So if you look at the use cases we have shipping deployed in production at scale for over six months renews agent that applies to renews team with predictive insights. This is LLM combination and machine learning. We have support with the engineers that all women that will support people to actually go what's the next best thing? Automate resolution of the low priority case without human touch at scale. I'm talking about 1.6 to 1.8 million cases a year. That is 60% of that is fully automated. And beyond that, integrating this directly on the product and sentiment analysis across the whole life cycle, which is an important thing. But I want to highlight with you. We have stuff that is deployed and Harrison is absolutely right. Experimentation and production are two different beasts. But he also talked about limited availability. So we interact with the end user. We have the subject matter experts and the cohort to work with us. So I understand more questions they're going to ask because the renews people is going to ask renews related question. The adoption people. Adoption related questions. It sounds obvious, but a lot of people don't think this way. They interact with the customer after they develop the cool stuff. You shouldn't do that. You should go to them before and say hi, what do you need? And then you build AI to help them. So but at the same time, even though we have limited availability and extending with the lanechain for the supervisor approach that we show we also have a lot that is on experimentation because we want to build pipelines for the new use cases that come. So those three things running well ideally on three different teams. And I'll touch upon this soon. So let me take one of those as an example on the renews assist the business value that we start. This is why do I need to build a renews agent. Well over half of my business is recurring revenue and I have a lot of time that these people is wasting just trying to chase dashboards and tools. So anything that I can give back and remove operational burden for them means and translates directly correlation with the financial results. Less time spending and doing useless stuff means more revenues that we're chasing. Means more business that not going untouched means higher results. There is a direct correlation to the business. Not hard to justify the investment you get. Right. And at the same time we wanted to correlate this with real time sentiment to the customers and provide some organizations that are high performance personalized to the person. So you are renewed on financial services industry. So I only explained what's the new trend for financial services which are completely different than a healthcare or a government people that deal with. So with that said we had over multiple 50 different data sets that were going around and a zoo of tools as you can imagine for every renew event. And the results for us was actually a reduction on 20% of the time use it in less than three weeks and limited availability. So the business impact was immediate and we have high accuracy of risk recommendation I was the one that the team loves and hates me at that point. And I said, we're going to go 95% accuracy and higher. And he accomplished that. We explained this yesterday and people on the booth can tell you how we got there. So let me go a little bit on the wheat. How did you do that? So let's go a little explain how the agentic flow works for us. So here's the question, typical question for the renews person. What's the upcoming renewed status for customer XYZ and the actions required to minimize its potential risk? It's a very fair question, but if you think about it, I need to know what's the customer then I need to know what products the customer wants. I need to know what dates this product, what bought so I can get the same circle of revenues. I need to understand what the current status and I need to map all the signals for the risk. And if the customer has multiple products, he may be happy with the product A, not happy with the product B, and maybe the renewals may be compromised or not. So there's a lot of signals and intelligence that goes from that. So having a single agent for this was not ideal because you don't get to the accuracy level that we're targeting. So we needed to go before supervisor was a thing on the Harrison this morning we came with a supervisor approach, which is basically receives the NLP and decomposes the nlp. And because the question is about a renewal agent, a renewals question, it hits the renewals agent immediately. Then the renewal agent gets that context and then he calls himself the adoption agent and the delivery agent to understand what's the status of the customer now. So I can answer half of the question on the pipeline and you can see this on the demo, on the length meeting, all the faces going and how we can compose the questions there so we can learn and leverage some of this. But that's active in parallel behind the scenes, not 100% autonomous yet, because we still still have human on the loop. But sentimental analysis is something that I can trigger anytime, right? If there is a question, I can proactively go and trigger the sentimentality and all the signals and come back, hey, this customer hates us, probably loves us or something like that, right? And at the same time, I, I want to make sure what is the install base that this customer has is a competitive guard into this because we open a breach, we have too expensive or we miss the functionality, whatever it is. So I'm talking about Cisco, but I appreciate the fact That a lot of you have a similar scenario on your projects, especially if you have repeated revenue and a lot of things that goes on. So then when you get out of the first part of the question and you get the real focus on customer experience at customer experience on any company is all about workflows. Support tickets follows a workflow. A renews process follows a workflow. Adoption follows a workflow. If you think about this, LLMs are not very good on workflows. They're good on LinkedIn. They're not metadata. They're trained on information that goes there. When you do Agent Equator tools like Langdraft platform, it helps a lot with that. So he went on this and you go to workflows and if the second part of the question is about risk, you. I hate a predictive machine learning model. Why? Because it's very deterministic. The LLM is very probabilistic. So he combined both to get to the accuracy level and we leverage the length change to make content scanning back and forth and led to me to trace it back going to the point that we receive the answer, we do the final reasoning formatting and answer it back to the internal reason. Now you can go differently and I don't have time for that. But I want to share you something. This our CX agentic AI in action. I have seven agents on that example. Over time we may decompose them. On some other agents, that's okay. The point of agent AI, a lot of people think about agents for us is less about the agent itself. It's more about the flexibility for the workflow. Think about this example. This is a question how can I maximize the value for all I invested in C in the last two years? That's a very fair question, but it's meant for an external customer, not an internal user. Same agents, different workflow. How can I dynamically change this for the understanding that's how the power, the supervisor and the naming agents go somewhere so you can see the agent power coming reality. And this is running in production. So if you have time I recommend you to go on the booth. You have Vince and amount I presented yesterday myself and others. That's going to show how you're running this environment in production. How many agents we have the interaction between the supervisors and the agents. We use multiple models, as I said, deployment on premen on the cloud and a predictive machine learning pipeline using predicted models and ML integrated with LLMs to accomplish the results that we want. With that said, I want to wrap this conversation share with you some key learnings and takeaways that we went through that process for us. So first thing that I would recommend you, as I mentioned before, please define the use cases and the metrics first. Don't jump on the bandwagon because there is a new tool on the weekend because next weekend is going to have a new one and your team is going to get excited and AI is moving at unprecedented speed, which is great, is amazing to be happening in our lifetime. But at the same time, if you define the use case, it's much better for you to measure it at the same time. Ranks, prompts, few shots, supervisor, fine tuning, chains come after you have the use case, there is a reason for them to exist. I'm stating the obvious, but you wouldn't believe how many times this is not used. Last on the right side, experimentation, writing, prototype, design key. Sometimes if you do have a team that's only focused on production, they have different metrics than the experimentation team. The experimentation team has a latitude and degree of freedom to try and fail and fail fast. So use that and have a dedicated team for evaluation too. I talk to my team and they know that you don't make the dog the custodian of the sausages. It doesn't work like that. So you want the evaluation team to have the golden data sets and be able to say hey, this stuff is not hitting the performance you need or the cost you need or the math you need. Because if it's the same thing, people blend among themselves. So create this isolation which helps you to achieve what you want. Last but not least, achieving high accuracy with stacks to SQL and Enterprises case is really really hard. The three letter acronym is called sickle and another three letter algonins called LLM. They don't go on a date, they don't get along, so boy, believe me, it is hard. So we actually leverage this snowflake context semantic context on Cortex just for the reference of metadata. But then normalize the date first. And if you believe on something that I'm saying, avoid using LLM for doing joints on SQL, avoid hike and inter agent context and collaboration is critical. It goes beyond ncp. MCP is great, but NCP needs to be evolved. It's part of the industry starting it's a Swiss cheese. For now we are working on this and both Cisco and LangChain has been championing an initiative that we put out there that's called Agency, which is a full architecture that we open source. The code is you can use if you want that goes beyond the only Sharing of LLM protocols. One of those could be HOA and all of those but it's how you leverage a semantically and syntactically across agents with a directory. When you go to the Internet, the fourth thing that happens, you go to a DNS server, right? There's no notion of DNS servers with agencies if you think about it. So bring all this notions or how you authenticate. You have an agent directory. We authenticate and make sure that you have this. There are companies that are working there in startups that are creating this Langchen and Cisco and others. On that slide we are proposing a full architecture open source so the industry go to change the address. With that said, I would like to thank you all for all the time that you have here. It's amazing too amazing conference. We have kings on the board and have the demo running production. If you go through the traces, brace yourself and let's go together. Thank you very much. Thank you, Carlos. Now let's invite Jen Leibi on stage. Speaker B: Hold. Speaker A: Executive director is at J.T. morgan Chase. They'll be sharing their store behind Ask. Speaker B: David, their multi agent system for investment. Speaker A: Research filled with line gravity. Please give them warm welcome. Speaker B: Good morning everyone. I really felt to be here today at the insurance conference. A big thank you to the organizers for putting together such a great event and for inviting us to be able to share our journey with you today. My name is David. I'm here with my colleague Janie from the J.P. morgan Private Bank. So at the private bank we're part of the investment research team and this is the team that's responsible for curating and managing lists of investment products and opportunities for our clients. Now when I talk about lists, we're now talking about a few dozen or a few hundred products. We talked about thousands of products, each backed by many years of very valuable data. So when we have such extensive lists of diverse products, questions are inevitable. And when there's a question, our small research team needs to go find some answers. So we go figuring around databases, materials, files, and we piece together the answers to the questions that come across our desks each and every day. Now, not only is this a very manual and time consuming process, but this limits our ability to scale and it really makes it difficult for us to really provide insights into the products that we have on our platform. So as a group we got together, we challenged ourselves, we said let's come up with a way to automate the investment research process, aiming to deliver precise and accurate results. Today, when you have a question, you come to me. Come to David and David will give you an answer. But tomorrow you'll be able to build Ask David, our AI powered solution designed to transform the way we answer investment questions. With Ask David, we're aiming to provide curated answers, insights and analytics delivered to you as quickly as you can ask a question. Now, I know you're all probably asking yourself, David, are you going to just put yourself out of your job? Not quite. What we're doing is we're building this tool to make our job easier and much more efficient. The stakes here are high. Billions of dollars of assets are at risk and we're committed to building a tool that not only meets but also exceeds the expectations of all of our stakeholders. Looking to the future, we're really excited about all the possibilities that AZ Data potentially brings to the table. So now to dive deeper into the technical magic behind azda. I'll turn it over to Jane who will walk you through the nuts and bolts of how we're making our vision a reality. And she might even let you in on what Ass David stands for. Because I promise you, I didn't name this after myself. Speaker C: Thank you, David. So Ask David is a domestic specific QA agent. So let's start with terminology analysis. First of all, we have decades of structured data. Those are the backbones of many up and ready production systems. Prior to the introduction of an agent, users have access to the same data, but they have to navigate through different systems and manually syndicate information. An agent can introduce efficiency and integrated user experience. Next, we have unstructured data. As a bank, we manage a vast amount of documentation including emails, meeting notes, presentations. With the rise of virtual meetings, we also have increasing amount of video and audio recordings. How do we make full use of that information? The advancement of LLM really bringing tremendous opportunity in this area. Lastly, as a research team we have proprietary models and analytics which are designed to be really derive insights and visualization to help decision making. Previously it will require a human expert to conduct this kind of analysis. And offering white glove service with the help of Agent, we can scale the insight generation and we can make our service available to more of our clients. Now imagine being a financial advisor in a client meeting and your client studying bring up the fund and ask you why it's terminated. Believe me, it's actually a very loaded question. So in the past you would reach out to the our investments research team, talk with Real David and then you figure out was the status change the history of the fund and what's the reason behind it, what's the Research about this fund with a similar fund. How do I curate these answers specifically for this client? And you will come up with that presentation yourself manually. With the help of an agent we can get access to the same data analytics, insights and visualization right in our video enable the real time decision making that is our vision of Ask David and appropriate guessing. David stands for Data analytics, visualization, insights and decision management system. So this is our approach to build up David which is a multi agent system. Starting from our supervisor agent which acts as the orchestrator, it talks with our end user, understand their intention and try to delegate the task to one or more sub agents in the team. The supervisor agent has access to both short term and long term memories so that can customize the user experience. It also knows when to invoke human in the loop to ensure the highest level of accuracy and also reliability. Next we have our strategy data agent. It will translate natural language into either simple queries or API calls and it will use large laundry model to summarize the data on top. Abstracted data is a little bit different from abstracted data. Usually it requires some kind of pre process, but as long as you save it and vectorize it put into a database, we can employ a RAP agent on top to effectively derive information. Lastly we have the analytics agent. We talked about our proprietary model and APIs. They are usually in the format of APIs or programming libraries. For a simple query that can be directly answered by API calls, we'll use a react agent and use APIs as tools. But for more complex queries we'll use test to code generation capabilities and use human supervision for the execution. This graph is our end to end workload starting with the planning note and you probably noticed there are two subgraphs over here. One is a general QA flow. So for any questions. For any general questions, for example how do I invest in go? It will go to the left hand side subgraph and if the question is regarding specific funds you will go to the right hand side flow. Each of the flow as you can see equipped with one supervisor a and a team of specialized agents. Once we retrieve the answer, you probably notice there's one node to personalize the answer and another node to do the reflection check. I will explain it in detail in an example to follow. The whole flow ends with summarization. So now back to our client question. Why was this phone terminated? This is how our agent can handle it. So as you can see on the right hand side the agent otherwise the farm was terminated due to a performance issue and you can actually click into the reference link to see more about the form performance and the reason behind it. What really happened behind the thing. From that planning node we start to understand this user query is related to a specific form. So it goes to the specific farm flow. The supervisor agent inside will be able to extract the found information as a context and understand that actually the dog search agent is right one to solve the problem. Once dog search agent get that information, it's going to trigger the tools underneath to get the data from MongoDB. Once we retrieve that information, the data and information will be personalized. The same is information can be presented in different way. Depends on who is asking. For example, we are talking about the termination reason over here. A due diligent specialist may demand a very detailed answer while a biker may just be general. So this personalization node will tailor the answer based on the user roles. Next we have the reflection node it use LLM judge to make sure that the answer we generated makes sense. If it doesn't, what do we do? We try again. So the last one, the whole flow ends with summarization. In the summarization node we do several things. We summarize the conversation, we update the memory and we return the final answer. So it was quite a journey working on this multi age agent application and we are very excited to share the lesson learned. Number one, Start simple and refactor object. I know I showed you a fairly complex diagram earlier, but we didn't really focus on building that diagram from day one. So day one you can see is a plan vanilla react agent. We try to understand how it works and from there we need to work on the specialized agent on the picture too, which actually is a rag agent. You can see we start to customize the flow. But once we get very comfortable with the performance of the specialized agent, we start to integrate that into our multi agent flow. In picture three with a supervisor and in the picture four that's our current stats, we actually have subgroups generated for specific kind of intentions. Right now we have two intentions, but we can scale easily with this architecture. So we I talked about fast iterations, but how do we know every iteration we're moving towards the right direction? The answer is evaluation driven development. So everyone knows that compared to the traditional AI projects, GMAI projects actually has shortened development phase. But we do have a long evaluation phase. Right. So our suggestion is to start early, think about the metrics, what kind of goal you want to achieve. As we are in financial industry, obviously accuracy is one of the most important Things and the continuous evaluation help you get that confidence. You are improving day by day. So there are additional tips I have over here based on our own experience of evaluation as you can see on the screen. Right. So the dark blue bars over here are coming from the metrics of evaluation on main flow and the green one is actually one example of our sub agent. So my tip number one is make sure you independently evaluate your sub agents. But the key for your evaluation is to find places to improve, right? This help you make figure out what so we claim to ehobel accuracy. Second point is there are depends on how you design your agents. Make sure you pick the right metrics. So if you have a summarization you may want to check whether your summarization is concise or not. So conciseness is one of the metrics you want to pick. If you are doing a two call, maybe you can have a trajectory evaluation instead. Here is a common myth I think especially if you're a developer, you're talking about tbd. I think a lot of people say that I just don't do it do that. It's a lot of work, right? But it's not the same in the evaluation. You actually can start evaluation with or without contours, it doesn't matter. There are so many metrics beyond just accuracy and each one of them will provide you some insight. And you know what, once you start doing evaluation you will have review. Once you start doing review, you actually can accumulate more of the ground truth examples. Lastly, we have large language model itself as judged in combination of human review. These automatic solutions really help us scale without adding too much burdens to our humans need to review large amount of AI generated answers. Talking about three our last lesson and then over here is about humans being loop. When you apply a general model to a specific domain, usually you will get less than 50% accuracy. But you can do a quick improvements like chopping strategies. You can change your searching algos and you can actually make improvement engineering that can get you to that 80% mark. From 80 to 90 we are using the workflow chain itself. We are creating the software so that we can fine tune certain kind of questions without impacting each other between 90% and 100%. That's what we call the last mile. And the last mile is always pallid miles. In terms of Genii applications, it may not be achievable to get that 100% mark right. So what do we do? So Q might in the loop is very important to us because we have billion dollars at stake and we cannot afford inaccuracy. In another words, ask David still consults with real David whenever needed. In conclusion, three takeaways for you. Iterate fast, evaluate early, keep humans being loop. Thank you so much. Speaker A: Excellent. Thank you, Jen and David.