LangChain Interrupt 2025 Conference Recap
The LangChain Interrupt 2025 conference brought together leaders and researchers to discuss the rapidly evolving landscape of Artificial Intelligence, with a significant focus on the development, deployment, and evaluation of sophisticated AI agents. A central theme was the emergence of the "agent engineer"—a new breed of builder adept in prompting, product development, software engineering, and machine learning.
I. Core Beliefs Shaping the Agentic Landscape (Harrison Chase, LangChain)
Harrison Chase of LangChain presented foundational beliefs guiding the development of intelligent agents:
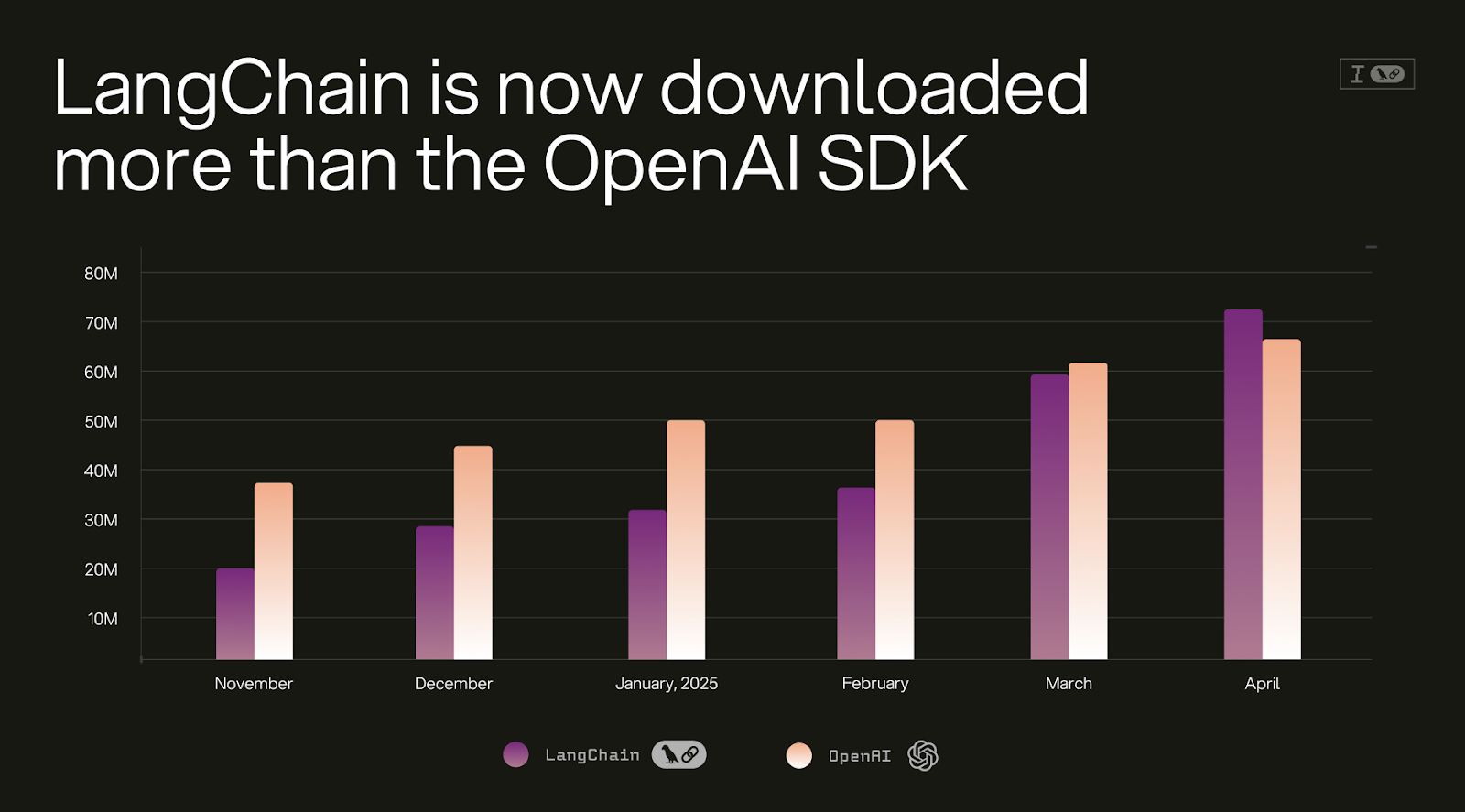
- Reliance on Diverse Models: The future of AI agents lies in their ability to leverage a multitude of AI models, each selected for its specific strengths in areas like reasoning, writing capabilities, speed, or cost-efficiency. LangChain positions itself as an essential integration hub, providing developers with the flexibility and "model optionality" needed to switch between and combine these diverse models. This trend is supported by data indicating that LangChain's Python SDK downloads have, at times, surpassed those of the OpenAI SDK, highlighting a strong developer preference for this flexibility.
 2. Context is Crucial for Reliable Agents: The reliability of an AI agent is directly tied to the quality and precision of the context provided to its underlying Large Language Models (LLMs). Effective prompting—which involves meticulously constructing this context from diverse sources such as system messages, user inputs, tool outputs, retrieval steps, and conversation history—is paramount.
2. Context is Crucial for Reliable Agents: The reliability of an AI agent is directly tied to the quality and precision of the context provided to its underlying Large Language Models (LLMs). Effective prompting—which involves meticulously constructing this context from diverse sources such as system messages, user inputs, tool outputs, retrieval steps, and conversation history—is paramount. LangGraph was introduced as a low-level, unopinionated framework designed to give developers granular control over this process of agent orchestration and context engineering.
3. Building Agents is a Team Sport: The creation of advanced AI agents is no longer a solo endeavor but a multidisciplinary effort requiring expertise in prompt engineering, product management, and machine learning. LangSmith is positioned as a collaborative platform offering integrated tools for observability, evaluations (evals), and prompt engineering to facilitate this teamwork.
II. The Evolving Landscape of AI Agents
The conference highlighted several key trends in the development and deployment of AI agents:
Agents are Gaining Traction
Contrary to the notion that 2025 would be the "year of agents," presenters indicated that 2024 marked the significant emergence of agentic systems into online and production environments. This is evidenced by the increasing volume of traces logged in LangSmith, signifying growing adoption and real-world application.
Distinct Nature of AI Observability
Monitoring AI agents presents unique challenges compared to traditional software observability. This is due to the large, unstructured, and often multimodal nature of the data agents process. The primary user of these observability tools is the "agent engineer," who requires insights integrating ML concepts, product considerations, and prompt engineering details. LangSmith is addressing this by launching new metrics for agent tool usage (run counts, latencies, errors) and trajectory observability.
Empowering a Broader Range of Agent Builders A concerted effort is underway to make agent development more accessible:
LangGraphPre-builts: Offering common agent architectures (e.g., single agents, agent swarms, supervisor agents) to help engineers without deep AI expertise get started.LangGraph Studio v2: A significantly revamped, web-based visual interface for building, testing, and debugging agents. It allows users to pull production traces fromLangSmithfor local modification and hot-reloading, directly view LLM calls in a playground, build datasets, and modify prompts.- Open Agent Platform: An open-source, no-code platform powered by
LangGraph. It utilizes agent templates, anMCP-based tool server,RAG-as-a-service, and an agent registry to enable non-developers to build agents.
Deployment as the Next Major Hurdle
As agents become more sophisticated—often involving long-running processes, bursty execution patterns, and statefulness for human-in-the-loop interactions—deployment emerges as a critical challenge. The LangGraph Platform, now generally available, is designed to tackle this by providing scalable and flexible deployment options (cloud SaaS, hybrid, fully self-hosted) with features like streaming, human-in-the-loop support, and robust memory management.
III. Key Architectural Concepts and Tools
Several architectural patterns and tools were consistently highlighted across presentations:
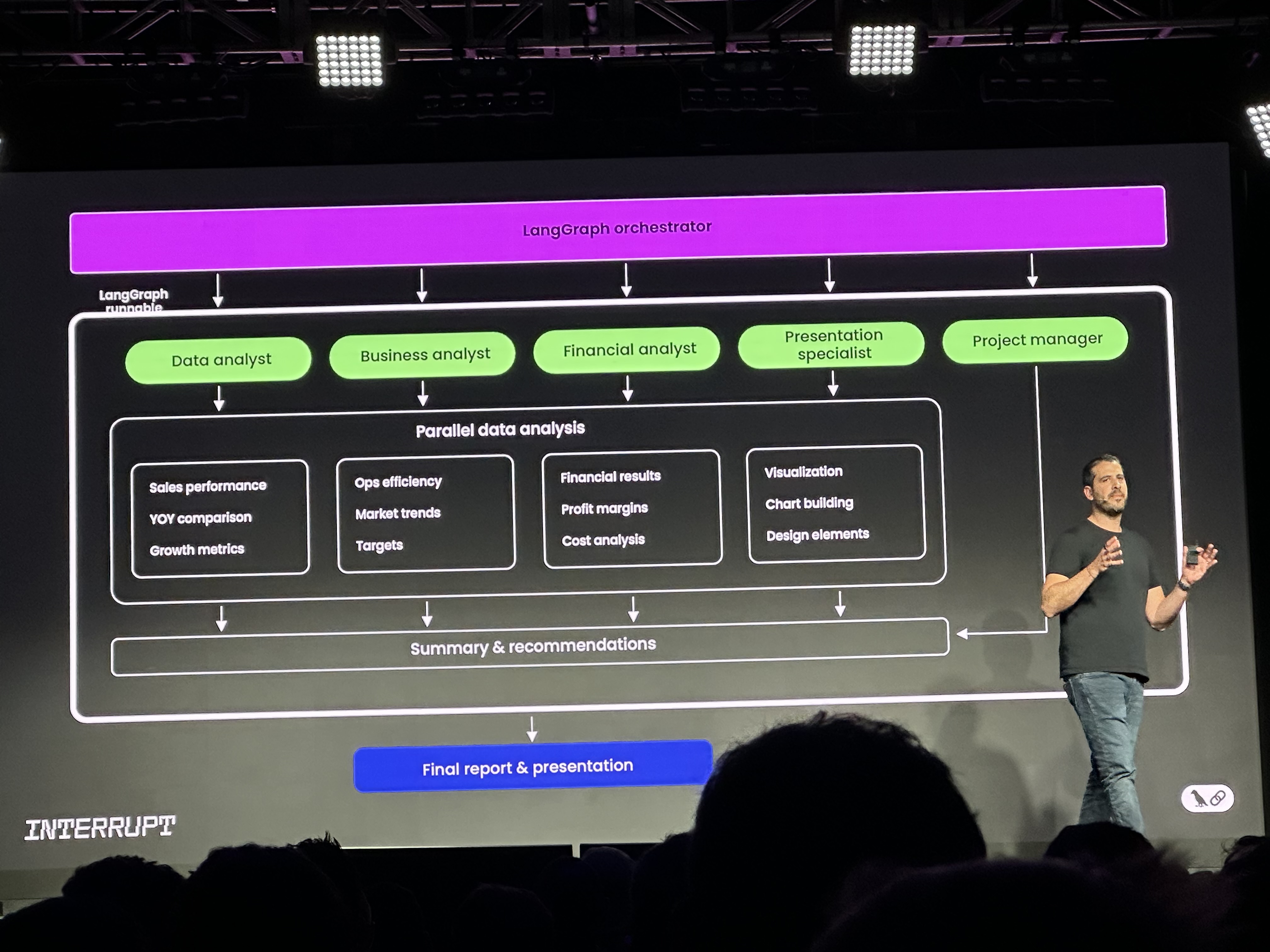
LangGraph Orchestrator
This conceptual tool illustrates how LangGraph can manage complex workflows by orchestrating specialized AI roles (Data Analyst, Business Analyst, Financial Analyst, Presentation Specialist, Project Manager) to perform parallel data analysis and generate comprehensive reports and presentations.
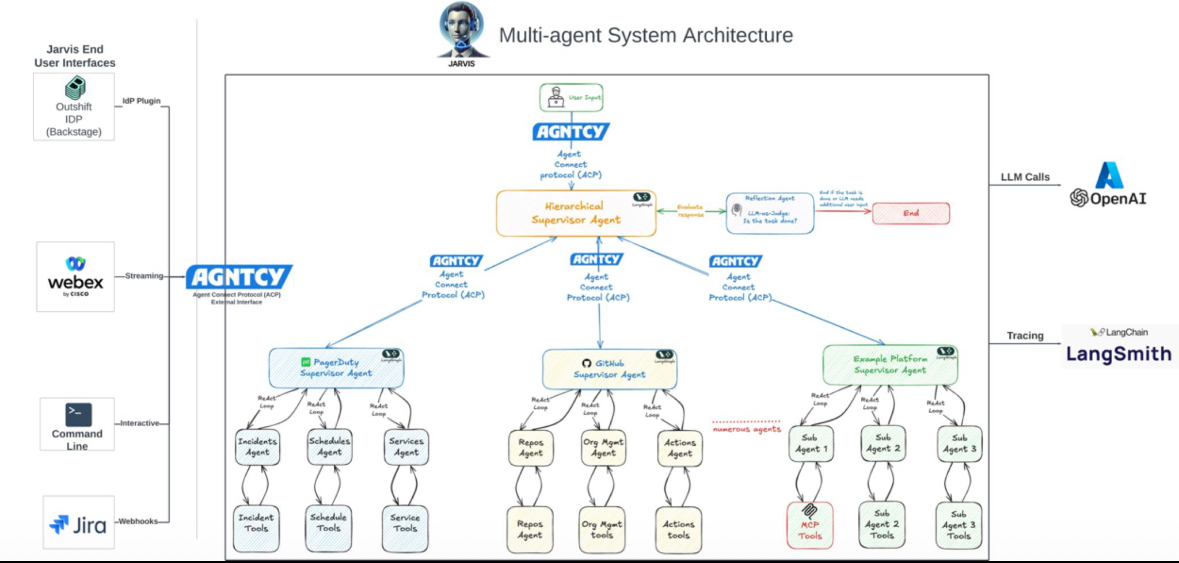
Multi-Agent System Architectures Hierarchical and collaborative multi-agent systems were a prominent theme:
- A "Jarvis" system depicted a Hierarchical Supervisor Agent coordinating various domain-specific supervisor agents (e.g., PagerDuty, GitHub) and their respective sub-agents and tools, with LLM calls and
LangSmithtracing.
- Cisco's CX Agentic AI stack integrates Generative AI Agents, Traditional AI Agents, and Human Agents via AI use-case workflows. These workflows leverage custom AI models trained on Cisco and third-party datasets and are designed for flexible deployment (on-premises, hybrid, cloud).

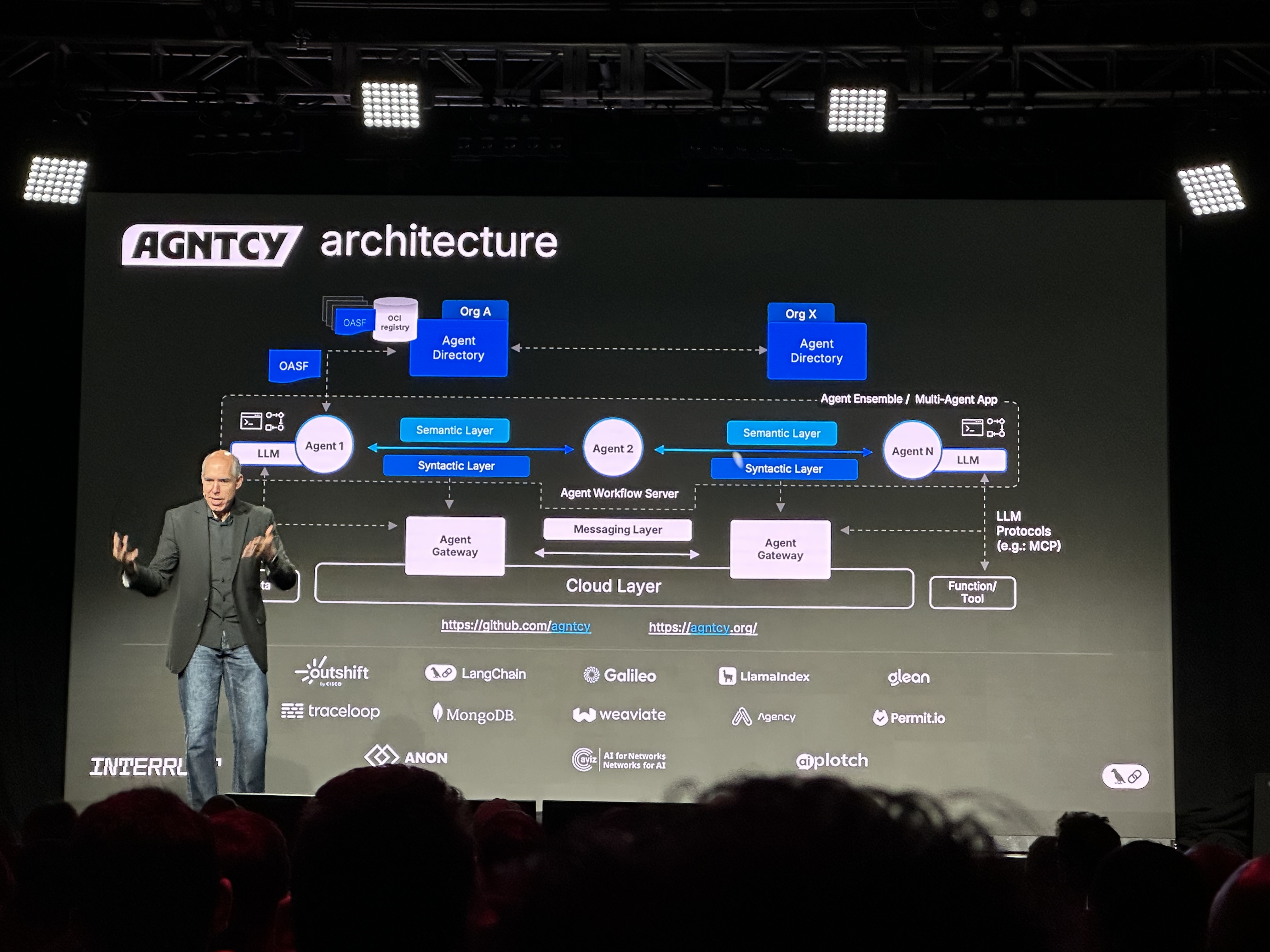
- The "AGNTCY architecture" showcased a cloud-native agent workflow server. This architecture features semantic and syntactic layers for agents, agent gateways for external communication (e.g., via LLM Protocols like
MCPor to Function/Tool endpoints), and integration with a variety of backend tools and services likeLangChain,Galileo, andWeaviate. It also includes anOASF (Open Agent Standard Format)registry and agent directories for different organizations.
Specialized Agent Modules (e.g., Box AI Extract Agent)
A presentation slide detailed an "Extract supervisor" within the Box AI Extract Agent. This supervisor intelligently prepares and groups fields, extracts field data using tools like eRAG and OCR across multiple models, and integrates a quality feedback loop involving an LLM as a judge for reflection and updates.
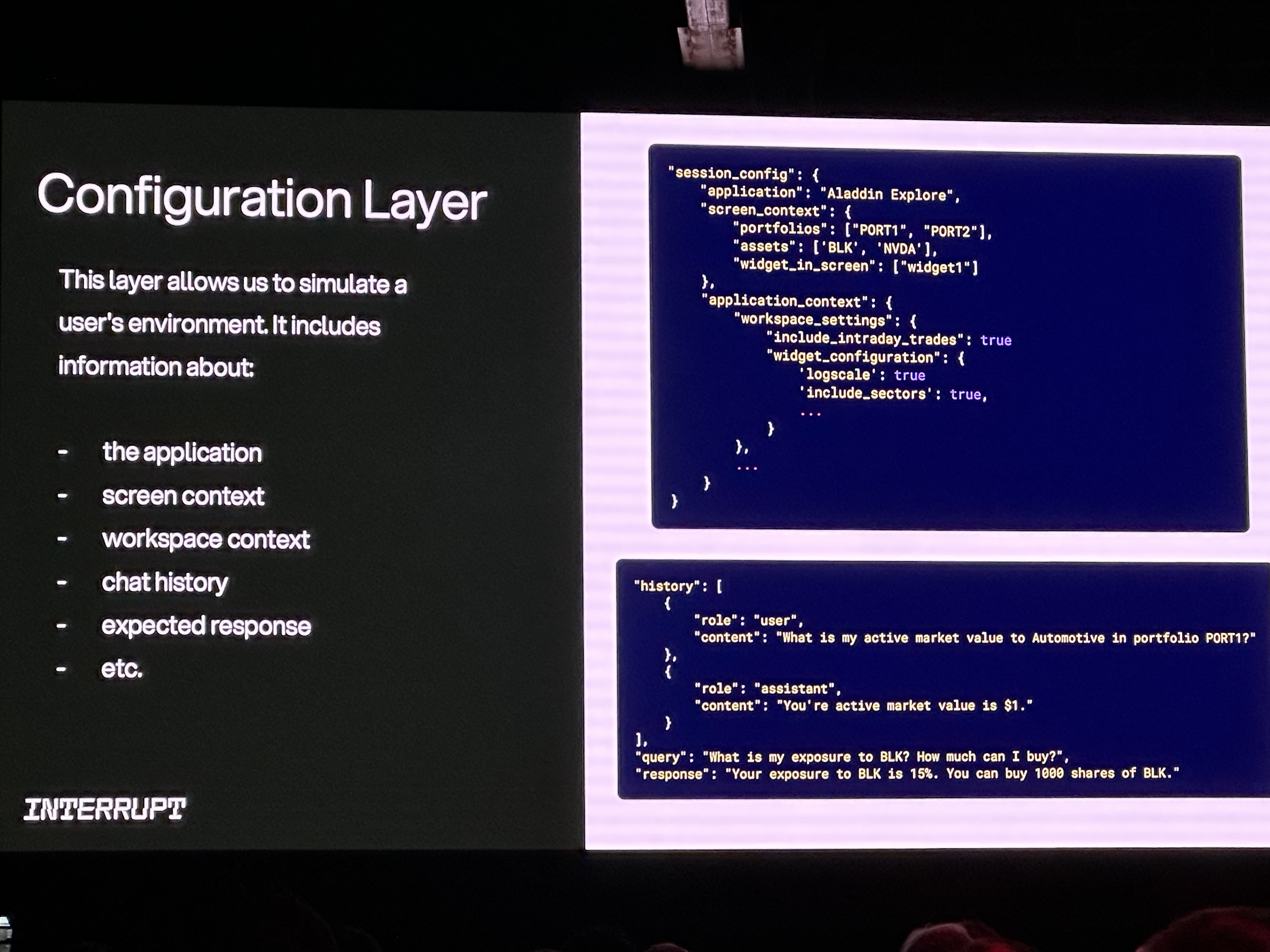
Configuration Layers for Realistic Simulation (e.g., BlackRock's Aladdin)
To ensure robust testing, systems like BlackRock's Aladdin Copilot employ a detailed "Configuration Layer". This layer allows developers to simulate complex user environments by defining parameters such as the application, screen context (portfolios, assets, visible widgets), workspace settings (e.g., include_intraday_trades), and chat history, ensuring agents are tested under realistic conditions.
IV. Evaluation as a Cornerstone of Agent Development
A significant portion of the conference was dedicated to the critical role of evaluation:
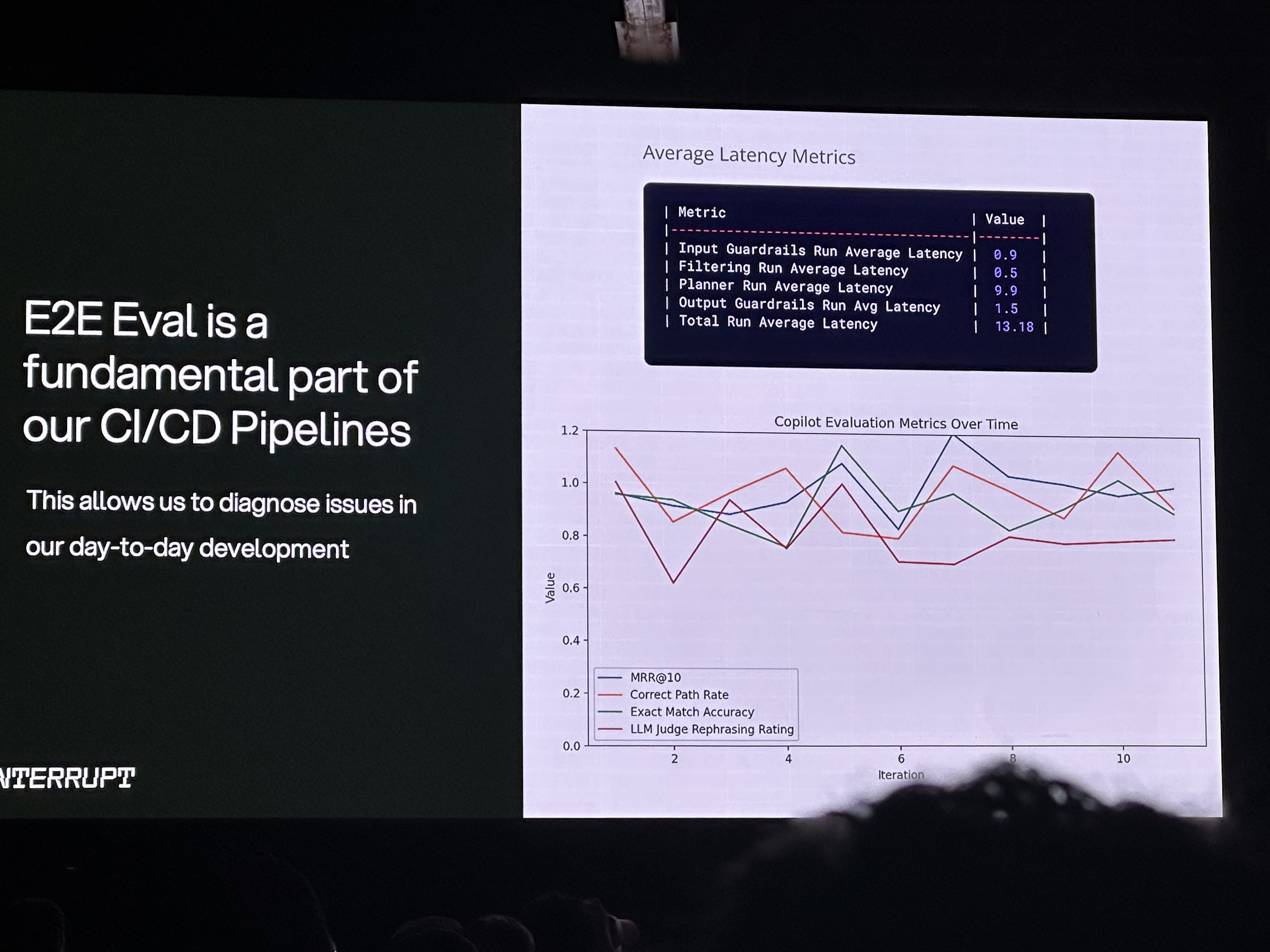
Eval-Driven Development
This was a recurring mantra, emphasizing the need to integrate evaluation throughout the entire development lifecycle. Tracking latency and various copilot metrics (MRR@10, Correct Path Rate, Exact Match Accuracy, LLM Judge Rephrasing Rating) over iterations helps diagnose issues.
Types of Evals
- Offline Evals: Pre-production testing against curated datasets.
- Online Evals: Real-time performance tracking on production data.
- In-the-Loop Evals: Agents self-correcting during runtime, crucial for high-stakes scenarios.
Data and Evaluators
Effective evals require both relevant data (often custom-built, as academic datasets may not represent real-world usage) and appropriate evaluators (code-based, LLM-as-a-judge, human annotation). LangSmith aims to simplify the creation of both.
LLM-as-a-Judge
While powerful for complex evaluations, these are tricky to set up and require careful calibration. LangSmith is introducing features based on research like "Align eval" and "Who Validates the Validators?" to improve their usability and reliability.
Human Judgment and "Taste" Despite advancements in automated evals, human preference judgments and qualitative feedback remain indispensable, especially for nuanced domains like legal AI where "taste" and subtle interpretations are critical.
V. Company and Research Highlights
Replit (Michele Catasta)
Discussed the evolution of Replit Agent v2 towards greater autonomy, the challenges of observability in complex agent systems ("assembly era of debugging"), and the strategic use of frontier models like Claude 3.5 Sonnet. Future work includes enhancing testing with computer vision and exploring test-time computation.
Andrew Ng (DeepLearning.AI)
Emphasized the "agentic" spectrum, the need for "tactile knowledge" in agent builders, the underrated potential of voice applications, and the increasing importance of coding skills for everyone interacting with AI. He also provided advice for AI startups, highlighting speed and technical depth as crucial.
Cisco (Carlos Pereira & Team)
Presented their "Agentic CX" framework, leveraging multi-agent systems for proactive and personalized customer experiences. They stressed a use-case-driven methodology and introduced their AGNTCY open-source architecture initiative for enhanced agent interoperability.
JPMorgan Chase (Zheng Xue, David Odomirok)
Showcased "Ask D.A.V.I.D.," their multi-agent system for investment research. Their journey highlighted iterative development, the centrality of evaluation-driven development in finance, and the non-negotiable role of human-in-the-loop for accuracy in high-stakes environments.
Cognition (Russell Kaplan)
Introduced "Devin," an AI software engineer designed for existing codebases. Key innovations include DeepWiki for code understanding and "Kevin Kernel," a CUDA-writing model optimized via RL, demonstrating that domain-specific fine-tuning can outperform larger foundation models. The challenge of "reward hacking" in RL was also noted.
Harvey (Ben Liebald)
Focused on the nuances of legal AI, where document complexity and the cost of errors are high. Their "lawyer-in-the-loop" approach, custom benchmarks (BigLawbench), and emphasis on capturing "process data" were key takeaways.
UC Berkeley (Shreya Shankar)
Addressed the "data understanding gap" and "intent specification gap" when users build data processing pipelines with LLMs. Her research aims to create tools for better anomaly detection, on-the-fly eval design, and interactive prompt improvement (e.g., Doc ETL project).
Monday.com (Assaf Elovic)
Discussed their "Digital Workforce" built on LangGraph and LangSmith. They shared crucial product/UX lessons: user control over autonomy, seamless integration into existing UIs, the importance of previews for building trust, and the need for explainability. They also highlighted the risk of "compound hallucination" with overly complex multi-agent systems and are exploring dynamic orchestration.
11x (Sherwood Callaway & Team)
Detailed the architectural evolution of their AI SDR "Alice," moving from ReAct to a workflow agent, and finally to a more flexible and performant multi-agent system (supervisor with specialized sub-agents).
Unify (Connor Heggie, Kunal Rai)
Shared their work on AI research agents, focusing on overcoming the challenges of agentic internet research by developing more sophisticated tools like "Deep Internet Research" and "Browser Access as a Sub-Agent".
VI. The Road Ahead
The LangChain Interrupt 2025 conference underscored that while the AI agent ecosystem is maturing rapidly, significant work lies ahead. Key future directions include:
- Enhanced Agent Interoperability: Moving beyond basic protocol sharing (like
MCP) to richer semantic and syntactic understanding between agents, as envisioned by initiatives like Cisco's AGNTCY. - Sophisticated Observability and Debugging Tools: Tailored specifically for the unique challenges of agentic systems.
- Simplified Agent Creation for Non-Experts: Through no-code/low-code platforms and pre-built architectures.
- Robust and Scalable Deployment Solutions: Capable of handling long-running, bursty, and stateful agent workloads.
- Capturing and Utilizing "Process Data": Training agents not just on outcomes, but on the nuanced workflows and decision-making processes of human experts.
In conclusion, the conference painted a vibrant picture of an industry actively building and deploying valuable AI agents. The collaborative spirit, coupled with powerful tools and evolving best practices, positions the field for continued transformative growth.